
בשנים האחרונות התרגלנו לשאול את הבינה המלאכותית כמעט הכול. איך לנסח מייל, איך להבין חוזה, איך לסכם מאמר, ולעיתים גם שאלה הרבה יותר רגישה: האם מה שאני מרגיש עכשיו מצריך טיפול רפואי?
זו אחת הנקודות שבהן ההתלהבות מבינה מלאכותית פוגשת את המציאות הכי חשופה שלה. אדם לא נכנס לצ׳אט עם תלונה רפואית כמו שאלה במבחן אמריקאי. הוא כותב מתוך כאב, חשש, בלבול, לפעמים עם מידע חלקי, לפעמים עם ניסוח לא מדויק, ולעיתים עם סימפטומים שלא ברור אם הם מטרידים או מסוכנים. המודל, מצידו, נדרש לעשות משהו שמערכות בינה מלאכותית אינן מצטיינות בו באופן טבעי: לא רק לענות, אלא להעריך סיכון בתוך עמימות.
מחקר חדש של Marvin Kopka ו-Marcus A. Feufel מהאוניברסיטה הטכנית של ברלין, שפורסם בכתב העת JMIR Biomedical Engineering באפריל 2026, מציע כיוון מעניין במיוחד. החוקרים לא ניסו רק להזין את המודל בעוד ידע רפואי, הם ניסו לשנות את צורת ההנחיה שניתנת לו, כך שתדמה יותר לאופן שבו בני אדם מיומנים מקבלים החלטות במצבים אמיתיים של חוסר ודאות.
כשהזהירות הופכת לברירת מחדל
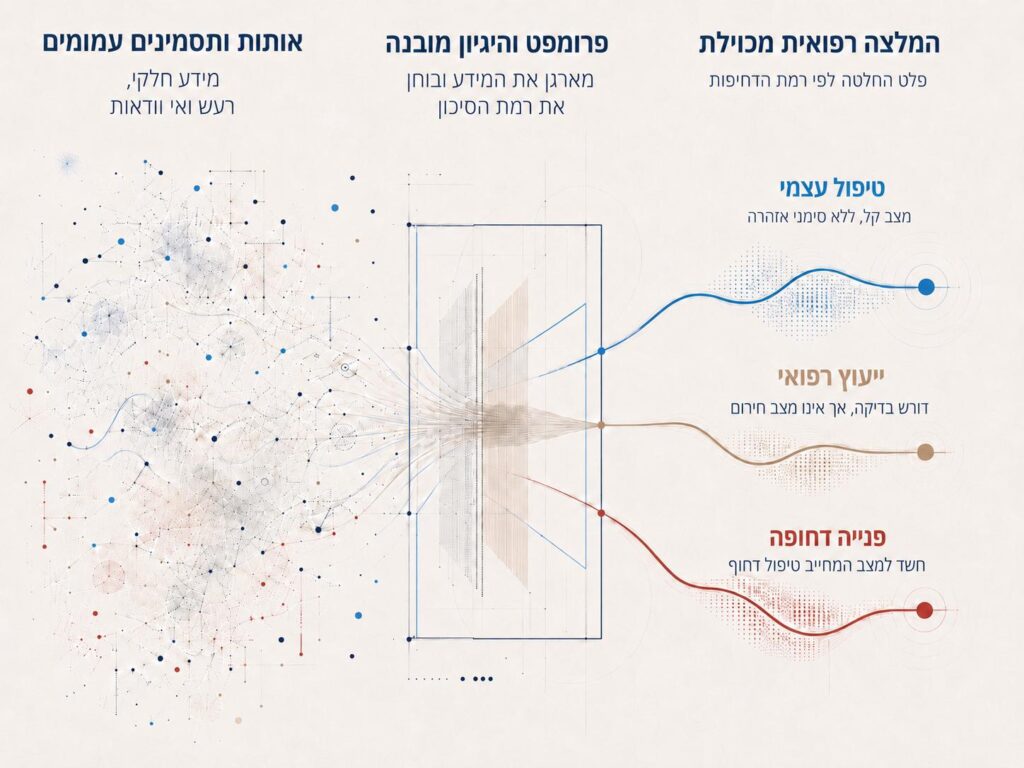
כאשר משתמש שואל צ׳אטבוט רפואי אם עליו לפנות לטיפול, התשובה הבטוחה ביותר מבחינת המודל היא כמעט תמיד: פנה לרופא, פנה למוקד או פנה לחדר מיון. במקרים מסוימים זו כמובן התשובה הנכונה, אבל אם זו ברירת המחדל כמעט בכל מצב, היא מפסיקה להיות הערכת סיכון אמיתית והופכת למנגנון הגנה.
התופעה הזו נקראת לעיתים הפניית יתר רפואית. כלומר, המלצה לפנות לטיפול מקצועי גם כאשר טיפול עצמי בבית היה יכול להספיק. לכאורה, זו זהירות. בפועל, זו עלולה להיות בעיה. היא יכולה להלחיץ משתמשים שלא לצורך, להעמיס על מערכת הבריאות, וליצור מצב שבו הכלי אמנם נשמע אחראי, אבל לא באמת עוזר להבחין בין מצב קל, מצב שמצריך רופא, או מקרה חירום. כאן בדיוק נכנס המחקר החדש. החוקרים בדקו אם אפשר לגרום למודל להיות לא רק זהיר, אלא מכויל יותר.
כשהפרומפט הופך למבנה חשיבה
רוב האנשים מדברים על כתיבת הנחיות לבינה מלאכותית כאילו מדובר בטריק ניסוחי. זה כמו לכתוב למודל ״פעל כרופא״, ״ענה בשלבים״, ״הסבר את עצמך״, בתקווה לקבל תשובה טובה יותר. אבל המחקר הזה הולך למקום עמוק יותר. הוא שואל לא רק מה לכתוב למודל, אלא איזו צורת חשיבה להפעיל בתוכו.
החוקרים הסתמכו על תחום בפסיכולוגיה קוגניטיבית שנקרא קבלת החלטות בסביבה טבעית (Naturalistic Decision-Making). הכוונה היא לחקר הדרך שבה בני אדם מקבלים החלטות בעולם האמיתי, לא בתנאי מעבדה נקיים. רופאים, כבאים, טייסים ואנשי חירום לא מקבלים החלטות כאשר כל הנתונים מסודרים לפניהם בטבלה. הם פועלים בתוך לחץ, מחסור בזמן, מידע חסר, והסתברות משתנה. במקום לבקש מהמודל רק לסווג תיאור רפואי, החוקרים ניסו להנחות אותו לחשוב בצורה שקרובה יותר למומחה אנושי: לזהות דפוס, לשאול אם המקרה דומה לתרחיש מוכר, לדמיין מה עלול לקרות אם לא תהיה פנייה לטיפול, ולבדוק אם הפרשנות הראשונית באמת מתאימה לכל הנתונים. זו נקודה חשובה כי במציאות הרפואית, התשובה הנכונה לא תמיד נוצרת מתוך כלל אחד, היא נוצרת מתוך התאמה בין תסמינים, הקשר, חומרה, זמן, סבירות, ודגלים אדומים.
דפוס או מסגרת: שתי דרכים להעריך מצב
המחקר בדק שתי גישות מרכזיות בתחום קבלת החלטות בסביבה טבעית בהשוואה להנחיה בסיסית ששימשה כביקורת. שתי הגישות קרובות, אבל הן מתחילות מנקודה אחרת. הראשונה היא קבלת החלטה לפי זיהוי דפוס (Recognition-Primed Decision-Making). במונחים פשוטים, היא מבקשת מהמודל לזהות תבנית מוכרת. האם המצב דומה למצב קל, למצב שמצריך רופא, או למצב חירום. לאחר מכן היא מבקשת לבדוק אם ההמלצה שמתאימה לדפוס הזה אכן סבירה. השנייה היא תאוריית המסגרת (Data-Frame Theory). כאן הרעיון מעט שונה. היא מבקשת מהמודל לבנות מסגרת להבנת המקרה: מה כנראה קורה כאן, אילו פרטים תומכים בכך, ואילו פרטים לא מסתדרים ומחייבים לשנות את המסגרת הראשונית.
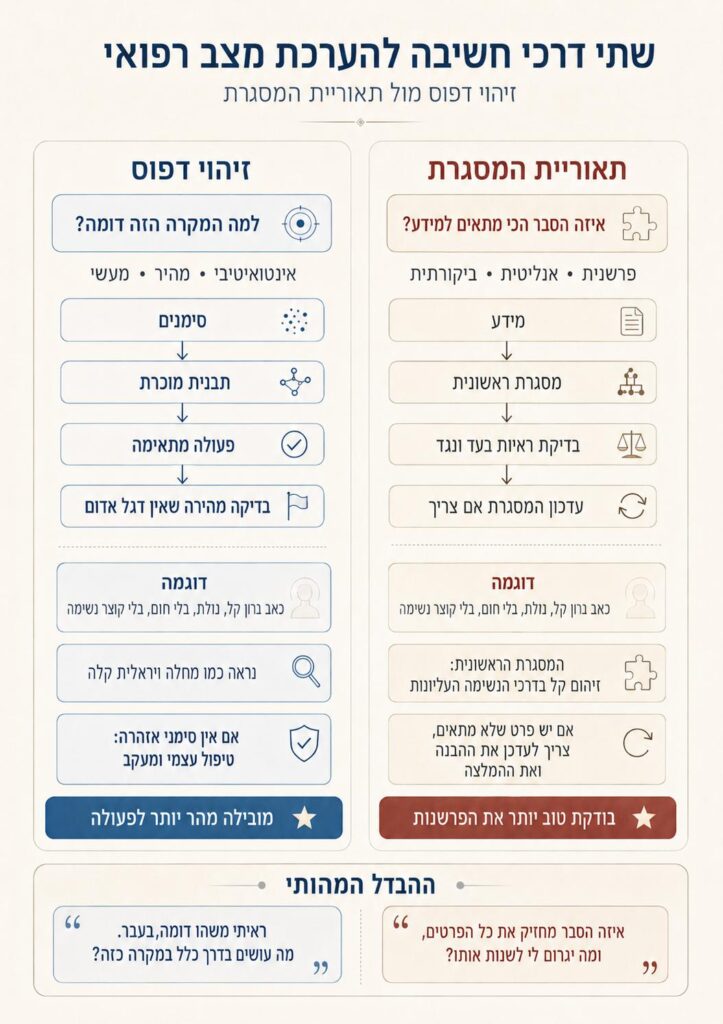
שתי הגישות מנסות להרחיק את המודל מתגובה כללית מדי כמו: ״כאבים בחזה יכולים להיות מסוכנים, פנה מיד״. במקום זאת, הן מנסות לגרום לו לבצע הערכת מצב מסודרת יותר: האם מדובר בכאב לוחץ חדש במאמץ עם קוצר נשימה, או בכאב מקומי אחרי תנועה, אצל אדם צעיר ובריא, ללא סימני אזהרה. כמובן, גם ההבחנה הזו אינה מחליפה רופא, אבל היא מדגימה את ההבדל בין תשובה זהירה באופן אוטומטי לבין ניסיון אמיתי להעריך את רמת הדחיפות.
פחות הפניות מיותרות, בלי לוותר על בטיחות
החוקרים בדקו עשרה מודלים שונים ממשפחת ChatGPT על 45 תרחישים של מטופלים, בשלוש רמות דחיפות: מצב חירום, מצב שמצריך טיפול רפואי שאינו דחוף, ומצב שבו טיפול עצמי עשוי להספיק. כל שילוב של מודל, תרחיש והנחיה נבדק עשר פעמים, כדי לבדוק גם יציבות ולא רק תשובה חד פעמית.
התוצאה המרכזית הייתה ברורה. כאשר המודלים קיבלו פרומפט ביקורת בסיסי, המלצה נכונה לטיפול עצמי ניתנה רק ב-13.4% מהמקרים. כאשר השתמשו בפרומפט המבוסס על קבלת החלטה לפי זיהוי דפוס, השיעור עלה ל-29.8%. שימוש בפרומפט המבוסס על תאוריית המסגרת העלה את השיעור ל-24.6%. כלומר, השיטה לא הפכה את המודל למושלם, אבל היא כמעט הכפילה את שיעור זיהוי המקרים המתאימים לטיפול ביתי.
המספרים האלה לא הופכים את המודל לרופא. הם גם לא הופכים אותו לכלי שאפשר לסמוך עליו באופן עיוור. אבל הם כן מראים משהו חשוב: לפעמים הבעיה אינה רק במודל עצמו, אלא באופן שבו אנחנו מפעילים אותו. חשוב לא פחות, החוקרים מדווחים שהשיפור בזיהוי מצבים שמתאימים לטיפול עצמי לא בא על חשבון זיהוי מצבי חירום או מצבים רפואיים שדורשים פנייה שאינה דחופה. כלומר, לפי המחקר, ההנחיות החדשות לא פשוט ״הרגיעו״ את המודל בצורה מסוכנת, אלא שיפרו את האיזון שלו.
לא רק ברפואה: בינה מלאכותית כשכבת החלטה
המשמעות של המחקר רחבה יותר מהשאלה אם צ׳אטבוט יודע לומר למישהו להישאר בבית או לפנות לרופא. הוא נוגע בלב הדיון על בינה מלאכותית כיום: האם אנחנו רוצים מערכות שרק מחזירות תשובה נכונה במבחן, או מערכות שיודעות להתמודד עם מצבים לא נקיים, לא מלאים ולא נוחים?
הרבה ממבחני הבינה המלאכותית עדיין בנויים כמו עולם סטרילי. שאלה, אפשרויות, תשובה נכונה. אבל החיים לא בנויים כך. גם עיתונאי, עורך, רופא, עורך דין, איש ביטחון או מנהל משבר לא מקבל תמיד בעיה מסודרת. הוא מקבל חלקי מידע. לפעמים גם מידע סותר. ההחלטה הטובה אינה בהכרח זו שנשמעת הכי בטוחה, אלא זו שמבינה את ההקשר. לכן המחקר הזה מעניין גם לעולם התקשורת. הוא מזכיר לנו שבינה מלאכותית אינה רק כלי לייצור טקסט. היא הופכת בהדרגה לשכבת תיווך בין אדם לבין החלטה. כשכלי כזה נכנס לתחומים כה רגישים, חשוב להבין אם הוא יודע להבחין בין ודאות מדומה לבין שיקול דעת אמיתי.
בין תרחיש מחקרי למטופל אמיתי
צריך להיזהר מהתלהבות יתר. המחקר נעשה על תרחישים מוגדרים יחסית, גם אם הם נועדו לדמות מצבים בעולם אמיתי. במציאות, אנשים כותבים אחרת. הם משמיטים פרטים, הם מגזימים או ממעיטים, הם מתארים כאב בצורה רגשית, והם לא תמיד יודעים מה חשוב ומה לא. החוקרים עצמם מציינים שיש צורך במחקרים נוספים שיבדקו אם ההנחיות האלה משפרות גם את החלטות המשתמשים בפועל, ולא רק את תשובות המודל בסביבת בדיקה.
וזו אולי הנקודה הקריטית ביותר. תשובה טובה של מודל אינה מסתיימת במודל, היא ממשיכה אל האדם שקורא אותה. האם הוא מבין את ההסתייגויות? האם הוא יודע מתי לא להסתמך עליה? האם ההסבר עוזר לו לחשוב טוב יותר, או דווקא נותן לו ביטחון מופרז?
בבריאות, הפער הזה יכול להיות מסוכן במיוחד. מודל שממליץ יותר מדי על חדר מיון יוצר עומס וחרדה. מודל שמרגיע יותר מדי עלול לפספס סכנה. האתגר הוא לא לבחור בין פחד לשאננות, אלא לבנות מערכות שיודעות לשמור על מתח נכון בין השניים.
כשהפסיכולוגיה נכנסת להנדסת הבינה
אחד המסרים החשובים במחקר הוא שהדרך לשיפור בינה מלאכותית אינה עוברת רק דרך מודלים גדולים יותר, יותר שבבים, יותר נתונים ויותר חישוב. כל אלה חשובים, אבל הם לא כל הסיפור. לפעמים השיפור מגיע דווקא מהבנה טובה יותר של האדם.
במקרה הזה, הפסיכולוגיה הקוגניטיבית נכנסת לתחום הנדסת הפרומפטים. לא כדי להפוך את המכונה לאדם, אלא כדי ללמד אותה לפעול טוב יותר במסגרת של בעיות אנושיות. זו הבחנה עדינה, אך חשובה. המודל לא ״מבין״ כמו רופא, אבל אפשר לעצב את הדרך שבה הוא ניגש לשאלה כך שהתשובה תהיה פחות מכנית ויותר מתאימה למציאות.
בעידן שבו בינה מלאכותית נכנסת לבריאות, משפט, חינוך, תקשורת וניהול משברים, זו אולי אחת השאלות החשובות ביותר: לא רק מה המודל יודע, אלא איזה סוג של שיקול דעת אנחנו גורמים לו לחקות. כי בסוף, אדם ששואל שאלה רפואית לא מחפש תשובה מרשימה. הוא מחפש משהו הרבה יותר בסיסי, לדעת האם עליו לדאוג, האם עליו לפעול והאם המערכת שמולו מבינה את ההבדל בין סימן חולף לבין סכנה.
המחקר הזה לא פותר את הבעיה. אבל הוא מסמן כיוון נכון יותר. פחות קסם טכנולוגי, יותר הנדסת שיקול דעת. פחות תשובות שנשמעות אחראיות, יותר ניסיון להבין מתי אחריות פירושה להרגיע, ומתי אחריות פירושה לומר: עכשיו צריך עזרה.
למאמר המחקר המלא שהוזכר בכתבה:
Kopka M, Feufel MA. Increasing Large Language Model Accuracy for Care-Seeking Advice Using Prompts Reflecting Human Reasoning Strategies in the Real World: Validation Study. JMIR Biomedical Engineering. 2026;11:e88053. doi: 10.2196/88053.
המאמר המקורי: https://biomedeng.jmir.org/2026/1/e88053
המאמר פורסם בגישה פתוחה תחת רישיון CC BY 4.0.












































































עדיין אין תגובות!