
לקרוא את עקבות החשיבה של הבינה המלאכותית
קבוצת חוקרים מהטכניון, בשיתוף NVIDIA Research, מציעה דרך חדשה להביט על מודלי שפה גדולים: לא דרך התשובה שהם מספקים, אלא דרך העקבות שהם משאירים בזמן שהם מגיעים אליה. מאחורי סדרת המחקרים עומדים חוקרים ובהם ד״ר חגי מרון מהפקולטה להנדסת חשמל ומחשבים בטכניון, ד״ר פבריציו פרסקה, ד״ר יפתח זיסר, פרופ׳ רן אל־יניב וחוקרים נוספים. העבודות התקבלו לכנסים המרכזיים בעולם הבינה המלאכותית, ובהם NeurIPS, ICLR ו־AAAI, והן מציבות שאלה בסיסית בהרבה מהדיון הרגיל על ביצועים: האם ניתן לזהות מתוך פעילותו הפנימית של מודל שפה את הרגע שבו הוא מתחיל לטעות.
הדיון הציבורי בבינה מלאכותית עדיין מתנהל בעיקר סביב הפלט. המודל ענה נכון או שגוי. המציא מקור או דייק. סיכם היטב או בלבל בין עובדות. אבל מודל שפה אינו קופסה שמכניסים אליה שאלה ומקבלים ממנה תשובה בלבד. בין הקלט לפלט מתרחש תהליך חישובי עצום: מיליארדי פרמטרים, שכבות עיבוד, מנגנוני קשב, התפלגויות הסתברות, תחרות בין מילים אפשריות ורצף החלטות צפוף שמוביל לבסוף למשפט שהמשתמש רואה. רוב המידע הזה נעלם ברגע שהתשובה נשלחת. המחקרים החדשים מתייחסים אליו לא כאל פסולת חישובית, אלא כאל חומר הגלם החשוב ביותר להבנת המודל.
הבעיה שממנה יוצאים החוקרים מוכרת לכל מי שמשתמש במודלי שפה. מערכות בינה מלאכותית מסוגלות לנסח תשובות משכנעות מאוד גם כאשר הן טועות לחלוטין. התופעה מכונה הזיה, אבל המילה הזאת לפעמים מסתירה את עומק הבעיה. לא מדובר רק בשגיאה עובדתית. מדובר במערכת שמסוגלת לייצר טקסט רהוט, עקבי ובטוח בעצמו, גם כאשר תהליך קבלת ההחלטות שלה סטה ממידע אמין. לכן השאלה החשובה אינה רק איך לזהות טקסט שגוי לאחר שנכתב, אלא איך לזהות את הסטייה בזמן שהיא נוצרת.
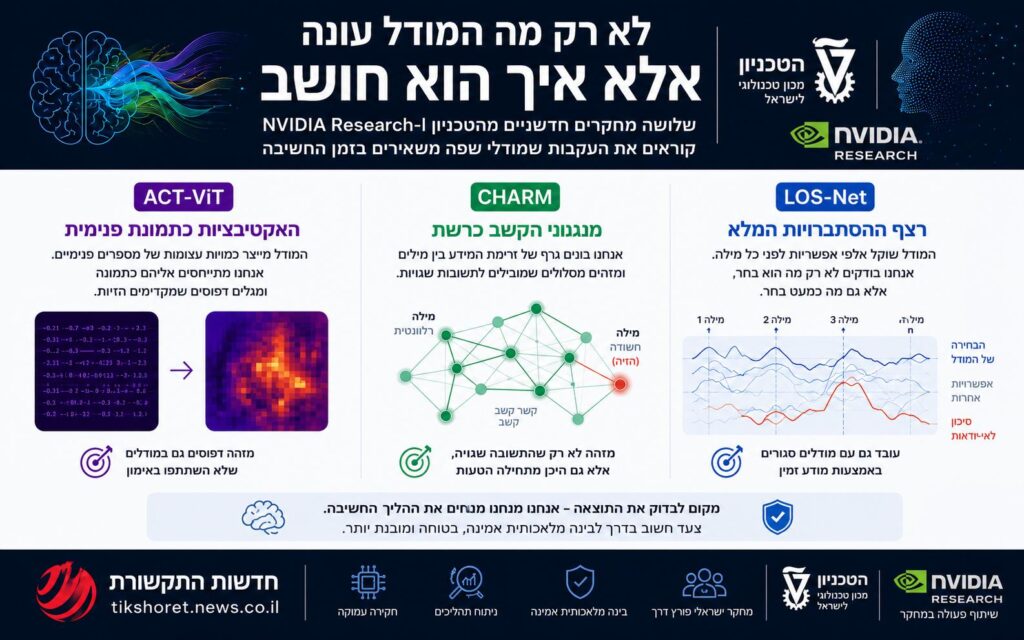
המחקר הראשון בסדרה, ACT-ViT, עוסק באקטיבציות הפנימיות של המודל. בכל פעם שמודל שפה מעבד משפט נוצרים בתוכו ייצוגים מספריים עצומים. אפשר לחשוב עליהם כעל מצב רגעי של המערכת בזמן החשיבה. גישות קודמות ניסו לחלץ מהם משמעות באמצעות כלים פשוטים יחסית, לעיתים מסווגים ליניאריים שבחנו נקודה אחת או שכבה אחת. קבוצת המחקר מציעה מבט רחב יותר: להתייחס לאקטיבציות כאל תמונה. לא תמונה במובן של צילום, אלא מבנה דו־ממדי עשיר בתבניות, אזורים ויחסים פנימיים.
המעבר הזה משנה את כלי העבודה. כאשר האקטיבציות נתפסות כתמונה, ניתן לנתח אותן באמצעות Vision Transformer, משפחת מודלים שפותחה במקור לעולם הראייה הממוחשבת. זהו מהלך חכם משום שהוא מפסיק לכפות על המידע צורה שאינה מתאימה לו. במקום לשאול איזה מספר בודד מנבא הזיה, המחקר שואל האם קיימת תבנית רחבה באזורים שונים של הפעילות הפנימית. התוצאות מצביעות על יכולת לזהות דפוסים הקשורים להזיות גם במודלים שלא שימשו לאימון המערכת. המשמעות האפשרית חריגה: ייתכן שטעויות במודלי שפה שונות חולקות חתימות פנימיות דומות.
המחקר השני, CHARM, עובר ממדידת פעילות פנימית למדידת זרימת מידע. בלב מודלי השפה המודרניים עומד מנגנון הקשב, Attention, שמאפשר למודל להחליט אילו חלקים בטקסט חשובים יותר בכל רגע. במשך שנים התייחסו למפות הקשב כאל כלי עזר מוגבל: אפשר לראות לאילו מילים המודל העניק משקל, אבל קשה להסיק מכך הסבר מלא. CHARM מציע לראות את הקשב כרשת. כל טוקן הוא צומת. כל קשר קשב הוא קשת. התוצאה היא גרף המתאר את האופן שבו מידע זורם בתוך המודל בזמן יצירת התשובה.
ההבדל אינו קוסמטי. כאשר מתייחסים לקשב כרשת, הטעות אינה נתפסת כרכיב בודד שפעל לא נכון, אלא כמסלול מידע שהתפתח באופן בעייתי. זו תפיסה קרובה יותר לניתוח מערכות מורכבות: רשת חשמל, מוח ביולוגי, תחבורה עירונית או מערכת פיננסית. השאלה אינה רק איזה צומת פעיל, אלא כיצד הקשרים ביניהם מייצרים התנהגות כוללת. באמצעות רשתות עצביות גרפיות ניתן לזהות מבנים החוזרים על עצמם כאשר המודל מתקרב לתשובה שגויה, ולעיתים אף למקם את האזור בטקסט שבו מתחילה ההזיה.
המחקר השלישי, LOS-Net, מרתק במיוחד משום שהוא נוגע גם למודלים סגורים. בשני המחקרים הקודמים נדרשת גישה למידע פנימי יחסית של המודל. במציאות המסחרית, רוב המודלים המובילים אינם חושפים את האקטיבציות או מנגנוני הקשב שלהם. LOS-Net מתמקד במידע קרוב יותר לפלט: התפלגות ההסתברויות שמאחורי כל מילה. כאשר מודל בוחר את המילה הבאה, הוא אינו בוחר אותה מתוך ריק. הוא מדרג אלפי אפשרויות. המשתמש רואה רק את המילה שנבחרה, אבל מאחוריה נמצאת רשימה ארוכה של מילים שכמעט נבחרו.
זהו אחד הרעיונות היפים בסדרה כולה. לפעמים מה שהמודל לא אמר חשוב כמעט כמו מה שאמר. שתי תשובות יכולות להיראות זהות מבחוץ, אבל לנבוע ממצבים שונים לגמרי. באחת המודל כמעט בטוח. באחרת הוא מתלבט בין חלופות רבות. ההסתברות של המילה שנבחרה לבדה אינה מספרת את כל הסיפור. רצף ההתפלגויות לאורך התשובה חושף היסוס, ביטחון, פיזור, תחרות בין חלופות ודפוסי החלטה שאינם גלויים בטקסט הסופי. LOS-Net לומד את הרצף הזה ומנסה לזהות דרכו הזיות, זיהום נתונים ודפוסים בעייתיים נוספים.
שלושת המחקרים שונים זה מזה, אבל כולם נשענים על אותו עיקרון. אקטיבציות הן לא רק מספרים; אפשר לקרוא אותן כתמונה. קשב הוא לא רק מטריצה; אפשר לקרוא אותו כרשת. הסתברויות פלט הן לא רק ציון למילה שנבחרה; אפשר לקרוא אותן כרצף החלטות. ההברקה אינה רק בבניית כלי חדש, אלא בהתאמת הכלי למבנה הטבעי של המידע. זהו מעבר ממחקר שמנסה להכריח את מודל השפה להסביר את עצמו במונחים אנושיים, למחקר שמנסה להבין את השפה המתמטית שבה המודל כבר מדבר.
החיבור לטכניון חשוב גם מעבר לקרדיט המוסדי. הטכניון נמצא שנים בצומת שבין מדעי המחשב, הנדסת חשמל, למידת מכונה ותיאוריה מתמטית. המחקרים הללו מבטאים בדיוק את החיבור הזה: לא רק יישום של בינה מלאכותית, אלא חקירה הנדסית־מדעית של המנגנון עצמו. שיתוף הפעולה עם NVIDIA Research מוסיף ממד תעשייתי משמעותי, משום שהשאלות האלה אינן נשארות במעבדה. הן יכריעו כיצד ייבנו מערכות AI שיפעלו ברפואה, פיננסים, משפט, תקשורת, תעשייה ושירותים ציבוריים.
המשמעות המעשית רחבה. עולם הבינה המלאכותית אינו יכול להסתפק במודלים שמספקים תשובות טובות רוב הזמן. ככל שהמערכות מקבלות תפקידים רגישים יותר, נדרש ניטור עמוק יותר של תהליך קבלת ההחלטות שלהן. לא רק בדיקה בדיעבד של התשובה, אלא זיהוי מוקדם של מצב פנימי בעייתי. לא רק דירוג איכות לפלט, אלא מדידה של הדרך שהובילה אליו. זה ההבדל בין בדיקת רכב אחרי תאונה לבין מערכת חיישנים שמזהה את התקלה לפני איבוד השליטה.
המחקרים אינם פותרים את בעיית הקופסה השחורה. הם מציעים דרך בוגרת יותר להתקרב אליה. ייתכן שלא צריך להבין כל פרמטר במודל כדי לדעת מתי הוא נכנס לאזור מסוכן. ייתכן שמספיק ללמוד לקרוא את הסימנים שהוא משאיר: דפוס באקטיבציות, עיוות בזרימת הקשב, התלבטות חריגה בהתפלגות המילים. זו אינה הבנה מלאה של “מחשבת” המכונה, אלא התחלה של אבחון.
במובן הזה, התחום מתקרב פחות להנדסת תוכנה קלאסית ויותר לנוירולוגיה של מערכות מלאכותיות. לא משום שמודלי שפה חושבים כמו בני אדם, אלא משום שגם בהם קיימת מערכת מורכבת שמייצרת התנהגות מתוך פעילות פנימית שקשה לראות בעין רגילה. המחקרים של קבוצת הטכניון ו־NVIDIA Research מציעים להתבונן בפעילות הזאת כראוי: לא כרעש, לא כתוצר לוואי, אלא כחלון אל תהליך קבלת ההחלטות עצמו.
המרוץ הבא בבינה מלאכותית לא יעסוק רק במי יבנה את המודל הגדול ביותר. הוא יעסוק גם במי יידע להבין אותו, לנטר אותו ולזהות את הרגע שבו הוא מתחיל לסטות. בעידן שבו מערכות AI הופכות לתשתית תקשורתית, עסקית וציבורית, זו כבר אינה שאלה מחקרית בלבד.
זאת גם שאלה של אמון.
בסופו של דבר, המחקרים הללו מציגים תופעה שקשה להתעלם ממנה: ככל שאנו לומדים יותר על התנהגותם הפנימית של מודלי בינה מלאכותית, כך אנו נתקלים בדפוסים שמזכירים יותר ויותר תהליכים אנושיים. לא משום שהמודל הוא אדם, אלא משום שבשני המקרים ניתן לזהות סימנים המעידים על איכות תהליך קבלת ההחלטות עוד לפני שמתקבלת התשובה עצמה.
אדם שמשהה תשובה מורכבת, אדם שעונה במהירות מוגזמת, אדם שמפגין ביטחון מוחלט דווקא כאשר הוא טועה, ואדם שבוחן חלופות רבות לפני שהוא בוחר תשובה אחת , כל אלה הם רמזים קוגניטיביים המאפשרים לנו להעריך את רמת האמינות של המסקנה עוד לפני שבדקנו אותה מול המציאות. המחקרים החדשים מראים כי גם במודלי שפה גדולים קיימים עקבות דומים: דפוסי הפעלה, מבני קשב, רמות אי־ודאות והתפלגויות הסתברותיות הנושאים מידע משמעותי על איכות החשיבה שהובילה לתשובה.
המשמעות חורגת בהרבה מזיהוי הזיות. היא נוגעת לשאלה האם ניתן יהיה בעתיד להעריך אמינות, זהירות, ביטחון, ספק ואפילו איכות שיקול דעת מתוך תהליך החישוב עצמו. במשך עשרות שנים עולם המחשוב התמקד בתוצאה. כעת מתחילה להיווצר יכולת לבחון את הדרך אליה. המעבר הזה עשוי להיות אחד השינויים החשובים ביותר בהתפתחות הבינה המלאכותית, משום שהוא מעביר את מרכז הכובד מן השאלה “מה המודל אמר” אל השאלה “כיצד המודל הגיע לכך”.
ההקשר הקוגניטיבי הזה מרתק במיוחד משום שהוא פותח דלת לשאלות שעד לא מזמן נראו כמעט בלתי ניתנות לחקירה. כיצד נוצרת טעות? כיצד נוצרת ודאות? מה מבדיל בין ניחוש לבין ידע? מה מבדיל בין הצלחה אמיתית לבין זיכרון סטטיסטי של מידע שנראה בעבר? אלו אינן רק שאלות הנדסיות. אלו שאלות הנוגעות לאופן שבו מערכות מורכבות מייצרות הבנה, קבלת החלטות וטעויות.
הטכניון ו־NVIDIA Research אינם טוענים שפיצחו את מוח הבינה המלאכותית. הם מצביעים על כיוון מחקרי חדש: מעבר מהתבוננות בתשובות להתבוננות בתהליך. במובן הזה, ייתכן שהמחקרים הללו חשובים פחות בגלל מה שהם כבר גילו, ויותר בגלל השאלות החדשות שהם מאפשרים לשאול. לעיתים זו בדיוק הנקודה שבה מתחילה פריצת דרך אמיתית.
קרדיט: המחקרים ACT-ViT, CHARM ו־LOS-Net פותחו במסגרת שיתוף פעולה מחקרי בין חוקרים מהטכניון לבין NVIDIA Research. חלק מהתרשימים, ההסברים והחומרים המחקריים שעליהם מתבססת הכתבה פורסמו באתר הטכניון ובפרסומי החוקרים. הכתבה מבוססת על עיבוד, ניתוח והנגשה עיתונאית של החומרים המקוריים לקהל הרחב.












































































עדיין אין תגובות!